
Sự khác biệt giữa khai thác dữ liệu và học máy | Khai thác dữ liệu và Học máy
Sự khác biệt chính - Thu thập dữ liệu và Học máy
Khai thác dữ liệu và học máy là hai lĩnh vực đi đôi với nhau. Khi chúng là mối quan hệ, chúng giống nhau, nhưng chúng có các bậc cha mẹ khác nhau. Nhưng hiện nay, cả hai đều ngày càng phát triển như nhau; gần giống như cặp song sinh. Do đó, một số người sử dụng máy tính học cho việc khai thác dữ liệu. Tuy nhiên, bạn sẽ hiểu khi bạn đọc bài báo này rằng ngôn ngữ máy khác với khai thác dữ liệu. Sự khác biệt chính là khai thác dữ liệu được sử dụng để lấy các quy tắc từ dữ liệu sẵn có, trong khi máy học dạy máy tính để tìm hiểu và hiểu các quy tắc nhất định .
Khai phá dữ liệu là gì?
Khai thác dữ liệu là quá trình trích xuất các thông tin tiềm ẩn, chưa biết trước và có thể có ích từ dữ liệu . Mặc dù khai thác dữ liệu nghe có vẻ mới nhưng công nghệ thì không. Khai thác dữ liệu là phương pháp chính để công bố tính toán các mẫu trong tập dữ liệu lớn. Nó cũng bao gồm các phương pháp ở giao lộ của học máy, trí tuệ nhân tạo, hệ thống thống kê và cơ sở dữ liệu. Trường khai thác dữ liệu bao gồm cơ sở dữ liệu và quản lý dữ liệu, xử lý dữ liệu trước, suy xét suy luận, xem xét phức tạp, xử lý sau các cấu trúc được phát hiện và cập nhật trực tuyến. Việc nạo vét dữ liệu, đánh bắt dữ liệu, và sáp nhập dữ liệu thường đề cập đến các thuật ngữ trong khai thác dữ liệu.
Ngày nay, các công ty sử dụng các máy tính mạnh mẽ để kiểm tra lượng dữ liệu lớn và phân tích các báo cáo nghiên cứu thị trường trong nhiều năm. Khai thác dữ liệu giúp các công ty này xác định mối quan hệ giữa các yếu tố bên trong như giá cả, kỹ năng nhân viên và các yếu tố bên ngoài như cạnh tranh, điều kiện kinh tế và nhân khẩu học của khách hàng.Sơ đồ quy trình khai thác dữ liệu CRISP
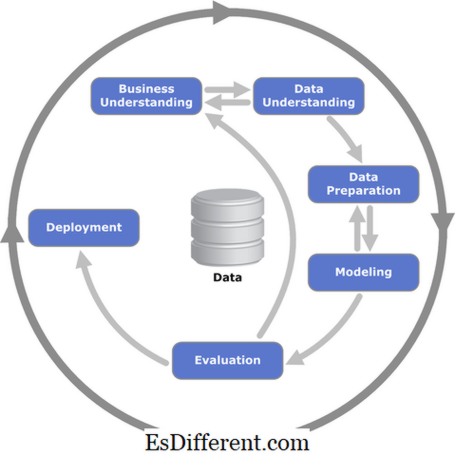
Học máy là một phần của khoa học máy tính và rất giống với việc khai thác dữ liệu. Học máy cũng được sử dụng để
tìm kiếm thông qua các hệ thống để tìm các mẫu, và khám phá việc xây dựng và nghiên cứu các thuật toán . Học máy là một loại trí thông minh nhân tạo cung cấp cho máy tính khả năng học hỏi mà không cần lập trình rõ ràng. Máy học tập chủ yếu nhắm vào việc phát triển các chương trình máy tính có thể dạy mình phát triển và thay đổi theo tình huống mới và thực sự gần với các thống kê tính toán.Nó cũng có mối quan hệ chặt chẽ với tối ưu hóa toán học. Một số ứng dụng phổ biến nhất của học máy là lọc thư rác, nhận diện ký tự quang học và công cụ tìm kiếm. Trợ lý trực tuyến tự động là một ứng dụng học máy
Học máy đôi khi mâu thuẫn với việc khai thác dữ liệu vì cả hai đều giống như hai mặt trên một con xúc xắc. Các công việc học máy thường được phân thành ba loại lớn như
học có giám sát, học không được giám sát, và học tập tăng cường . sự khác biệt
giữa Khai phá dữ liệu và Học máy là gì? Cách họ làm việc
Khai thác dữ liệu:
Khai thác dữ liệu là một quá trình bắt đầu từ dữ liệu phi cấu trúc để tìm các mẫu thú vị. Học máy:
Học máy sử dụng rất nhiều thuật toán. Dữ liệu
Khai thác dữ liệu:
Khai thác dữ liệu được sử dụng để trích xuất dữ liệu từ bất kỳ kho dữ liệu nào. Học máy:
Học máy là đọc máy liên quan đến phần mềm hệ thống. Ứng dụng
Khai thác dữ liệu:
Khai thác dữ liệu chủ yếu sử dụng dữ liệu từ một tên miền cụ thể. Học máy:
Các kỹ thuật học máy khá chung chung và có thể được áp dụng cho các thiết lập khác nhau. Tập trung
Khai thác dữ liệu:
Cộng đồng khai thác dữ liệu chủ yếu tập trung vào thuật toán và ứng dụng. Học máy:
Các cộng đồng học máy học trả nhiều hơn vào các lý thuyết. Phương pháp
Khai thác dữ liệu:
Khai thác dữ liệu được sử dụng để lấy quy tắc từ dữ liệu. Học máy:
Học máy học dạy máy tính để học và hiểu các quy tắc nhất định. Nghiên cứu
Khai thác dữ liệu:
Khai thác dữ liệu là một khu vực nghiên cứu sử dụng các phương pháp như học máy. Học máy:
Học máy là một phương pháp được sử dụng để cho phép máy tính làm các công việc thông minh. Tóm tắt:
Khai phá dữ liệu so với Học máy
Mặc dù việc học máy hoàn toàn khác với khai thác dữ liệu, chúng thường tương tự nhau. Khai thác dữ liệu là quá trình trích xuất các mẫu ẩn từ dữ liệu lớn, và học máy là một công cụ cũng có thể được sử dụng cho điều đó. Lĩnh vực học hỏi máy ngày càng phát triển như là kết quả của việc xây dựng AI. Các dữ liệu Miners thường có một sự quan tâm mạnh mẽ trong học máy. Cả hai, khai thác dữ liệu và học máy, cộng tác đều cho sự phát triển của AI cũng như các lĩnh vực nghiên cứu.
Hình ảnh được phép:
1. "Sơ đồ Quy trình CRISP-DM" của Kenneth Jensen - Tác phẩm của chính mình. [9]> [2] "Tác giả trực tuyến tự động" của Bemidji State University [Public Domain] qua mạng ĐMCĐ
